Using AI, a team of researchers has identified a thermoelectric material that potentially possesses favorable values. The group was able to navigate AI’s conventional pitfalls, giving a prime example of how AI can revolutionize materials science.
Details of their finding were published in the journal Science China Materials on March 8, 2024.
“Traditional methods of finding suitable materials involve trial-and-error, which is time-consuming and often expensive,” proclaims Hao Li, associate professor at Tohoku University’s Advanced Institute for Materials Research (WPI-AIMR) and corresponding author of the paper. “AI transforms this by combing through databases to identify potential materials that can then be experimentally verified.”
Still, challenges remain. Large-scale material datasets sometimes contain errors and overfitting the predicted temperature-dependent properties is also a common error. Overfitting occurs when a model learns to capture noise or random fluctuations in the training data rather than the underlying pattern or relationship. As a result, the model performs well on the training data but fails to generalize new, unseen data. When predicting temperature-dependent properties, overfitting could lead to inaccurate predictions when the model encounters new conditions outside the range of the training data.
Li and his colleagues sought to overcome this to develop a thermoelectric material. These materials convert heat energy into electrical energy, or vice versa. Thus, getting a highly accurate temperature-dependence is critical.
“First, we performed a series of rational actions to identify and discard questionable data, obtaining 92,291 data points comprising 7,295 compositions and different temperatures from the Starrydata2 database – an online database that collects digital data from published papers,” states Li.
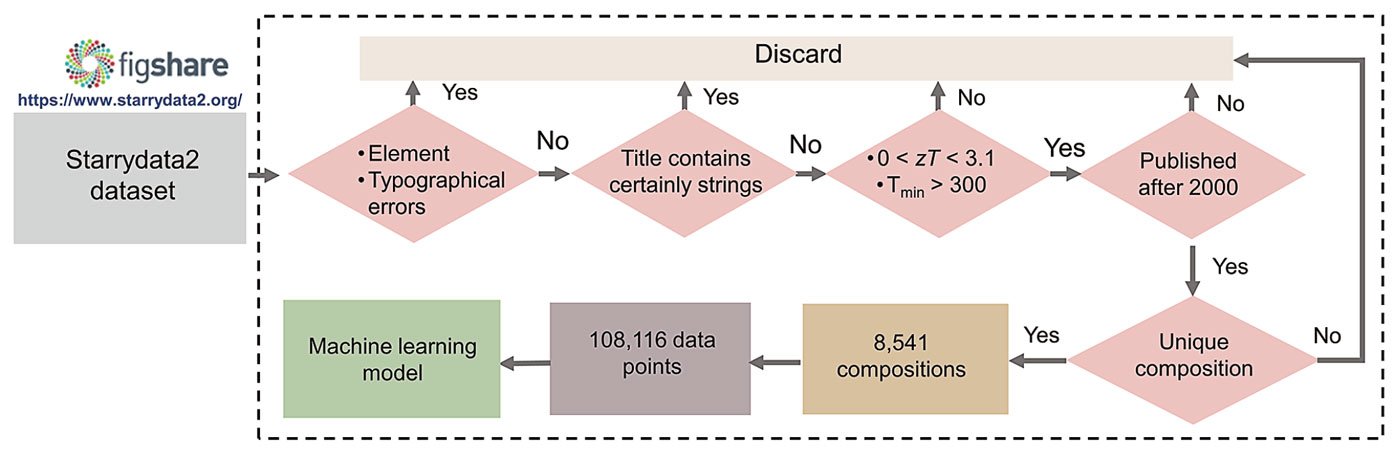
Following this, the researchers implemented a composition-based cross-validation method. Crucially, they emphasized that data points with the same compositions but different temperatures should not be split into different sets to avoid overfitting.
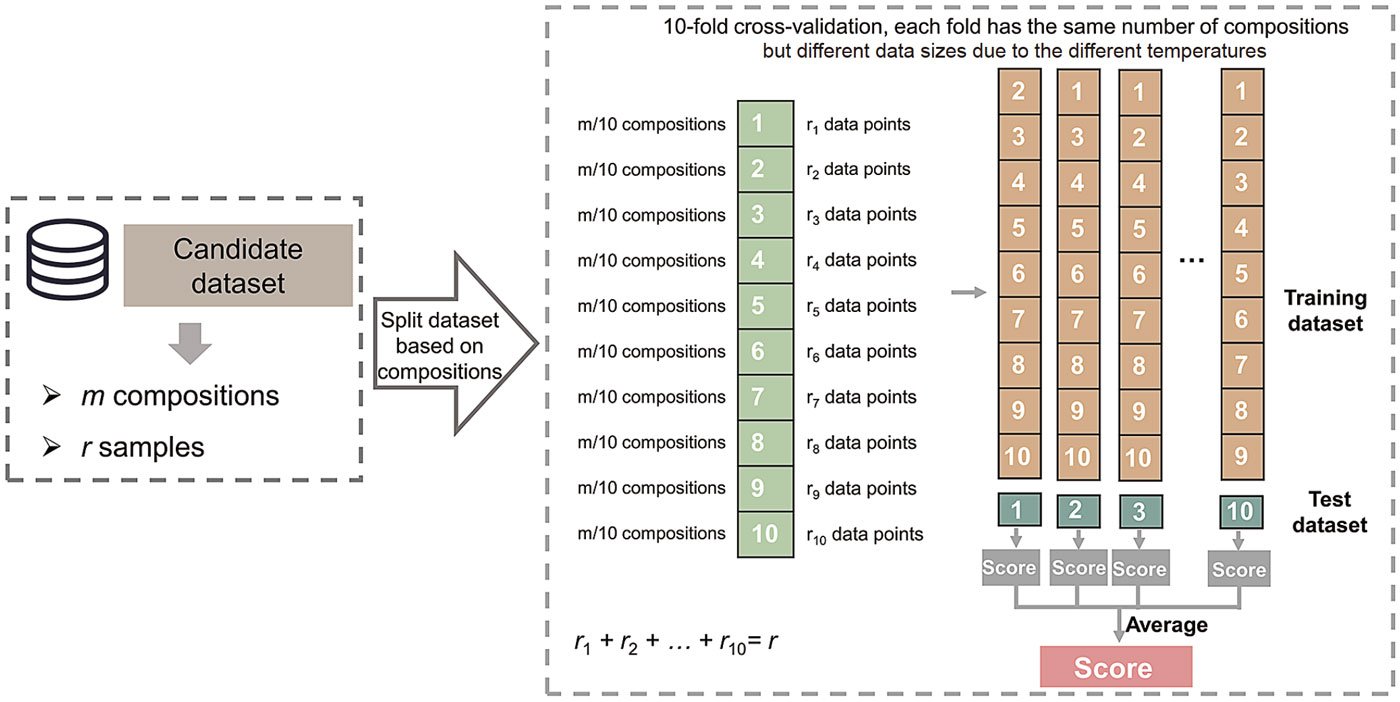
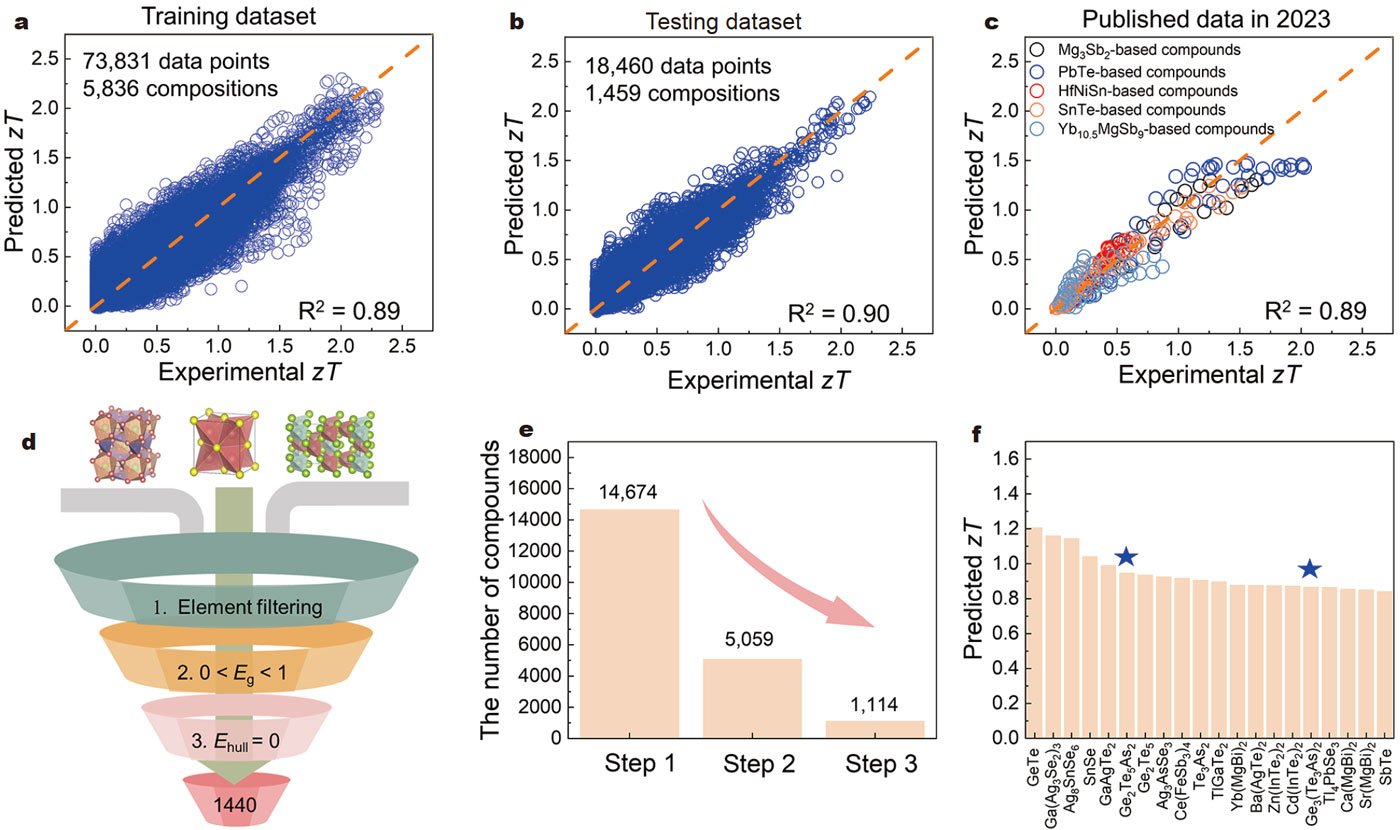
Then the researchers built machine building models using the Gradient Boosting Decision Tree method. The model achieved remarkable R2 values 0.89, ~0.90, and ~0.89 on the training dataset, test dataset, and new out-of-sample experimental data released in 2023, demonstrating the models accuracy in predicting newly available materials.
“We could use this model to carry out a large-scale evaluation of the stable materials from the Materials Project database, predicting the potential thermoelectric performance of new materials and providing guidance for experiments,” states Xue Jia, Assistant Professor at WPI-AIMR, and co-author of the paper.
Ultimately, the study illustrates the importance of following rigorous guidelines when it comes to data preprocessing and data splitting in machine learning so that it addresses the pressing issues in materials science. The researchers are optimistic that their strategy can also be applied to other materials, such as electrocatalysts and batteries.
- Publication Details:
Title: Dealing with the big data challenges in AI for thermoelectric materials
Authors: Xue Jia, Alex Aziz, Yusuke Hashimoto, Hao Li (Corresponding Author)
Journal: Science China Materials
DOI:




